Module 6 - Tutorial - Correlation & Models
import pandas as pdimport numpy as npCorrelation
Correlation is the relationship between one feature (column) to another. Features can be positively correlated, meaning that they both move in the same direction (if one increases, so does the other and if one decreases, so does the other) or negatively correlated, meaning that they move in opposite directions (if one increases, the other decreases). Correlation values are on a scale from -1 to 1. Features that are positively correlated are closer to 1 and features that are negatively correlated are closer to -1. All features are perfectly positively correlated (exact value of 1) with itself.
Location = gradedata.csvdf = pd.read_csv(Location)df.head()#creates a table of correlation valuesdf.corr()Linear Regression
Linear regression is used to predict the numerical value(s) for a target variable (the column that is being predicted). With one column as a predictor, a linear regression model is mathematically represented by the formula:
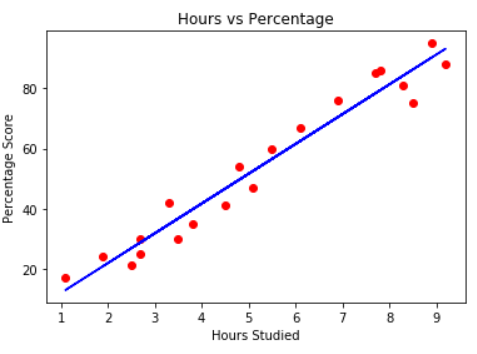
formula not implementedWhere y is the target variable, x is the predictor, m is the slope (weight of x), and b is the y-intercept, which is the starting value of y when m*x=0. Below is a linear regression line graphed to predict student grades based on the number of hours studied for an exam.
Source: Stack Abuse
{kind=link}
#use this library to build a statistical test for linear regressionimport statsmodels.formula.api as smf#OLS is Ordinary Least Squares, the most common type of linear regression#the fit function uses the predictive values to calculate the best linear regression lineresult = smf.ols('grade ~ age + exercise + hours', data=df).fit()#the summary will show the calculated values (slopes and y-intercept) for the linear regression formula#the closer to 1 the r-squared value is, the better the fit of the linear regression line#the p-value shows how statistically significant a predictive feature could be the modelresult.summary()With age, exercise, and hours being 0, your starting grade is likely to be around 57.87
#remove age from regression, since it was not very correlated to other featuresresult = smf.ols('grade ~ exercise + hours', data=df).fit()result.summary()#add age back into formula#remove y-intercept (set it to be 0)result = smf.ols(formula='grade ~ age + exercise + hours - 1', data=df).fit()result.summary()